
機械学習を行う上でデータの取扱いは重要です。
そこでまず知っておきたいことは、整然データと雑然データの違いです。
整然データ (tidy data)とはハドリー・ウィッカム (Hadley Wickham) 氏が提唱したものです。
データセットを作成する場合には整然データを意識して作成しておけば後々データ分析しやすいデータセットができます。
一般的に縦持ちデータと呼ばれるデータは整然データの場合がありますが、必ずしもそうではありません。横持ちデータは雑然データと考えて良いと思います。
整然データとは
ハドリー・ウィッカム氏の整然データの定義は次のとおりです。
- 各列の項目が変数であること
- 各行が1回の観測であること
- 観測のユニット単位の型が1つだけの表になる
- 個々の値 (value) が1つのセル (cell)
これだけでは何を言っているのかよくわかりませんので、例を加えて見ていきます。
各列の項目が変数
表の列名が変数になっているか調べます。列名に値が使われているとそれは雑然データです。
下表では商品名、年代、購入数などは変数です。この変数に対する値は同じ列の行に格納していきます。
他の例として列名に男、女としてしまうのではなく、性別とするべきだということです。
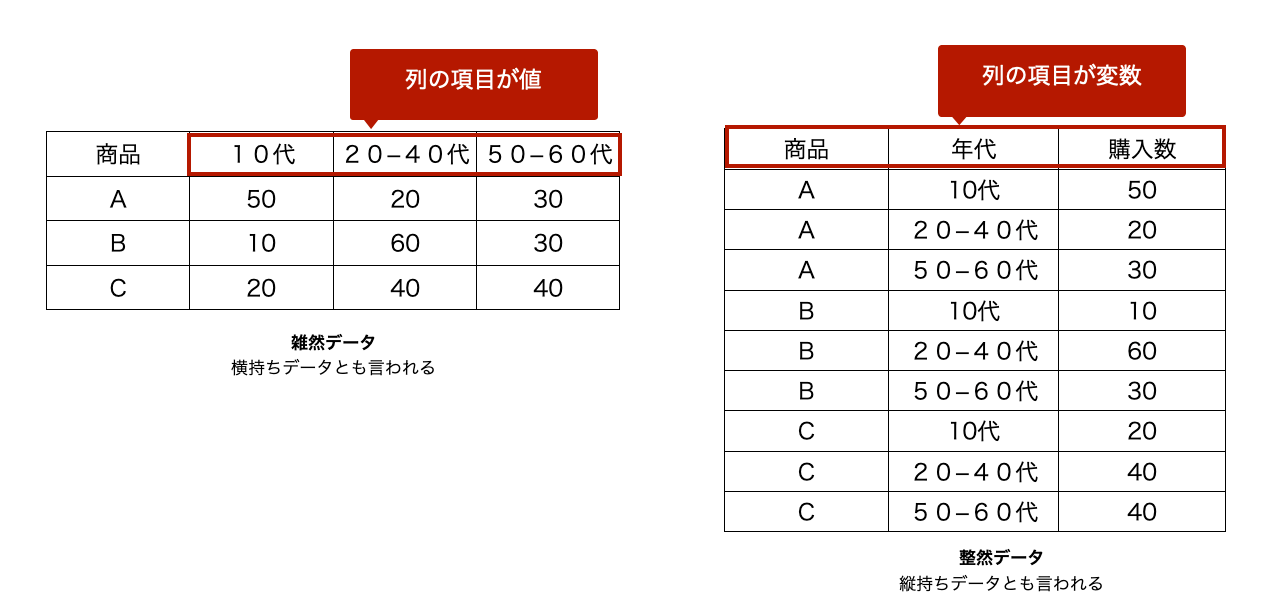
各行が1回の観測
同じ観測の値が1行に複数入っているとそれは雑然データです。下表では年代という観測データが1行に複数入っています。
これはつまり、列の項目が変数になってないということです。

観測のユニット単位の型が1つだけの表
観測のユニットとはある観測の集合ことで、複数の観測を一つの表にするのではなくできるだけ単一の観測の表に分けるということです。
そして分析の必要に応じてマージなどをすれば良いわけです。

個々の値 (value) が1つのセル
これは一つのセルに複数の値を入れないということです。下表では一つのセルに男女別の値が入っています。
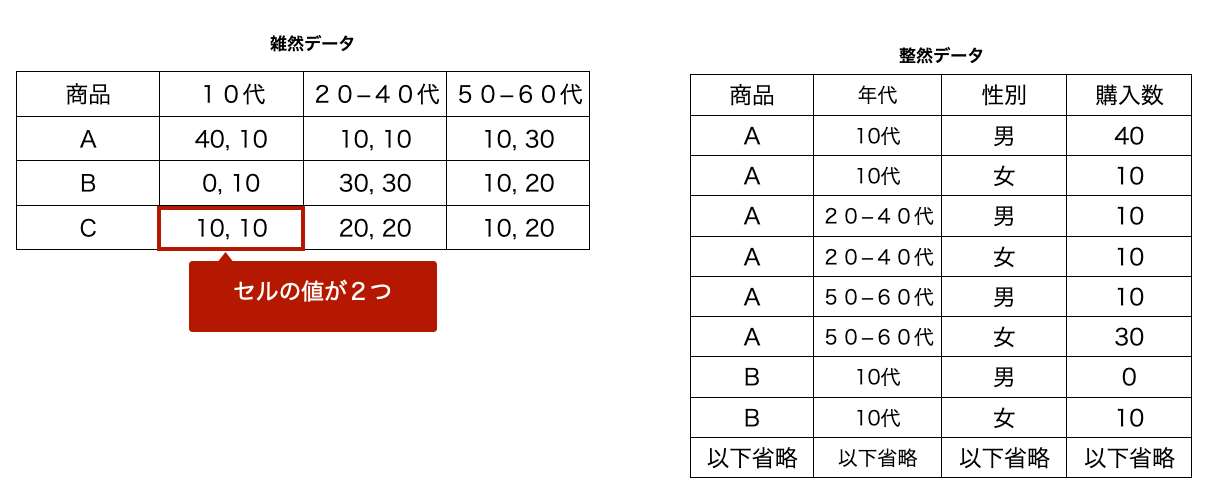
整然データが出来上がると、分析しやすいようにマージ、グループ化、ピボットなどを活用して様々な角度からデータ分析します。また機械学習するデータとして扱いやすくなります。
参考になった書籍
次の書籍には整然データの解説があります。



コメントを投稿するにはログインしてください。